youtube는 비디오를 어떻게 저장하는가
October 18, 2022
요약 #
- 서버는 마이크로 서비스로 python, c, c++, java, go로 작성되어 있다.
- DB는 Vitess 로 돌리는 MySql 사용.
- Memcache 는 Caching에 사용.
- Zookeeper 는 node co-ordination.
node co-ordination이 뭐지?
데이터 흐름 #
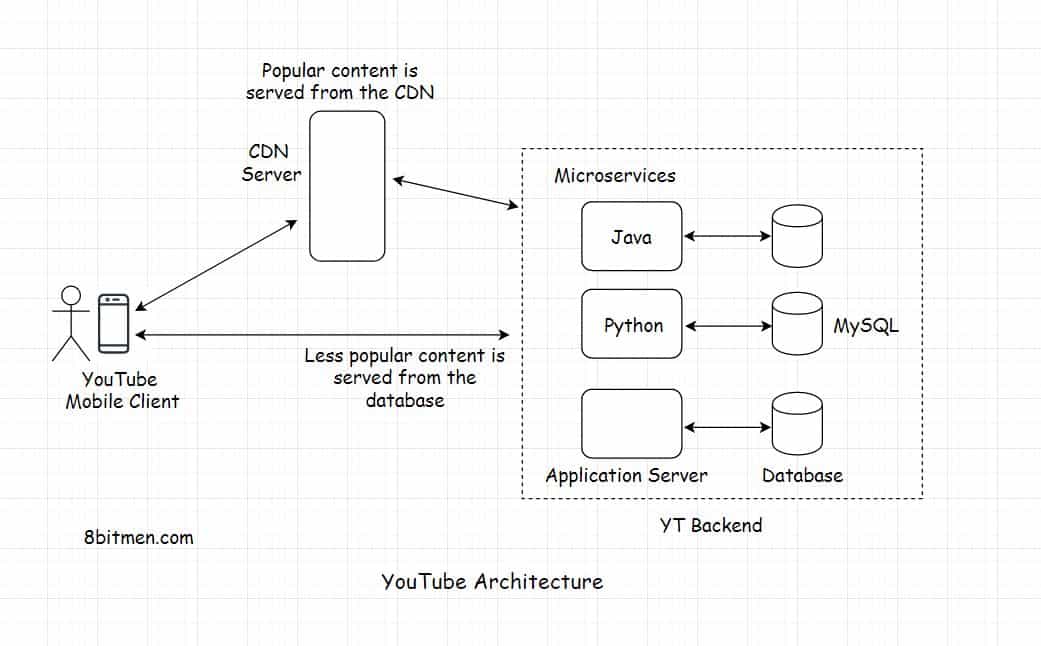
Figure 1: 유튜브 아키텍쳐
자주 요청되는 비디오는 CDN server에 두고 별로 인기 없는 비디오는 DB에서 직접 가져온다.
시작점 #
- 유튜브는 2005년 시작했고 2006년 11월 구글에 인수되었다.
- 구글에 인수되기 전에는 2명의 시스템 관리자, 2명의 소프트웨어 설계자, 2명의 기능 개발자, 2명의 네트워크 엔지니어, 1명의 DBA 로 구성되어 있었다.
- youtube도 당연하지만 하나의 DB 인스턴스에서 출발했다.
- 많아지는 요청에 따라 수평적으로 RDB를 확장해야할 필요를 느낌.
주인-노예 복제 전략 #

- DB를 여러 인스턴스로 복제함
- 원본 DB에서만 입력(쓰기)을 받는다. ( 원본 DB를 master라고 부름 )
- 원본 DB가 복제된 DB로 입력된 데이터를 넣어준다. ( 복제 DB를 replica라고 부름)
- 출력(읽기)는 복제된 DB와 원본 DB 모두에서 수행된다.
이 구조에는 문제가 있는데 master와 replica가 기록하고 있는 데이터가 다른 시점이 존재하게 된다는 것이다. master에 입력된 데이터가 replica에 업데이트 되기 전에 플레이 가능한 비디오 목록 요청이 들어오면 업데이트 이전의 데이터 목록을 유저에게 전송하게 된다. 하지만 유저는 별로 신경쓰지 않는다. 선택한 비디오가 제대로 틀어지기만 하면 되는것이다. 시간이 지나면 master와 replica 사이의 데이터 차이는 결국 같아진다.
하지만 이 master-slave replication 전략에도 한계가 있는 것 같다.
앱이 대박나서 입소문을 타고 사용자들이 급증한다. 너도 나도 자기 동영상을 업로드하기 시작한다. 그러면 하나의 master DB로는 쓰기 작업의 부하를 혼자 감당하지 못하게 될 것이다. 그럼 이제 어떻게 해야할까?
Sharding (조각내기) #
다음 전략은 DB를 쪼개는 것이다. #
Sharding은 관계형 DB를 확장하는 여러 방법 중 하나이다.
앞서 설명한 master-slave replication외에 master-master replication, federation & de-normalization 등이 있다 고 하는데 나머지는 머리 아프니 다음에 알아보자. 데이터들을 수평적으로 여러 머신에 쪼개서 보관하고 관리하자. 그렇게 하면 DB가 받는 부하가 나눠진다.
예를 들면 User 데이터만 다루는 서버와 Payment 데이터만 다루는 서버를 나누어 API를 통해 데이터를 교환하게 만드는 식이다. 하지만 서버를 분산한다는 것은 쉬운 일이 아니다. 원하는 데이터를 추출하기 위해서는 쪼개진 DB 서버끼리 네트워크를 통해 소통해야 함으로 지연되는 시간이 생겨 속도가 저하된다. 또한 복잡해진 구조 때문에 관리도 어려워진다.
그럼에도 불구하고 서비스가 성장하게 되면 해야하는 일이다. 기하급수적으로 높아지는 QPS(query per second)를 하나의 DB, 하나의 서버가 물리적으로 감당할 수가 없다. DB 쪼개기를 성공적으로 마쳤다면 이제 쓰기 작업을 여러 대의 서버 컴퓨터에서 나눠서 처리할 수 있게 되었다.
너무 고맙게도 앱 사용자가 더 늘어난다. 너무 많은 양의 데이터가 한 번에 마구 쏟아진다. 근데 나눠놓은 서버 중에 하나가 열이 받았는지 내가 뭘 잘못했는지 자꾸 꺼진다. 나도 열이 받는다. 어떻게 해야할까?
재난 관리 #
세상에는 예측 못할 일들이 너무 많다. 갑자기 지진이 나서 서버 컴퓨터가 다 고장날 수도 있고 중국 산업 스파이가 컴퓨터를 통째로 들고 튈수도 있다. 하지만 대비할 수 있다.
전 세계에 여러 대의 데이터 센터를 두면 된다. 그리고 데이터들을 동기화한다. 전 세계에 데이터 센터를 나눠두게 되면 사용자 요청에 좀 더 빠르게 대응할 수 있다는 점이 또 다른 이점이다. 서울에서 요청된 데이터는 서울에 위치한 데이터 센터에서 보내주고 유럽에서 요청된 데이터는 유럽의 데이터 센터에서 보내준다.
최적화되지 않은 full table scan query들은 종종 모든 데이터베이스를 죽이기도 한다. 나쁜 쿼리들로부터 보호되어야 한다. 모든 서버들은 효율적인 서비스를 보장하기 위해 추적되어야 한다. 이제 인프라가 너무 복잡해졌다. 머리 아프다. 개발자들은 이 모든 복잡성을 추상화한 시스템이 필요하다.
최소한의 노력으로 관리하고, 확장도 더 쉽게 하고 싶다. 이제 어떻게 할까?
Vitess #
SqlDB의 수평적 확장이 가능하게 하는 쿠버네티스 기반 DB 관리 시스템 #
유튜브, 슬랙, 깃헙, 스퀘어 등에서 사용된다. Go로 작성됨.
Vitess는 개발자가 직접 DB 쪼개기 로직(만약 payment DB의 부하가 50% 이상이면 하나의 payment DB 서버를 더 생성해줘)를 직접 앱에 작성하지 않아도 된다. Sharding 기능이 내장되어 있다. Fail-Over(장애 발생시 예비 시스템 가동)와 Backup도 자동으로 수행한다. 또한 해당 자원에 집중적인 쿼리로 재작성해주고 데이터를 캐싱해주는 등의 방식으로 DB 성능도 높여준다.
RDB의 ACID, 일관성을 가지는 동시에 noSQL처럼 쉽게 수평 확장을 이루고 싶다면 Vitess가 필요하다.
클라우드에 배포하기 #
vitess는 클라우드 환경이 기본이다. 클라우드 네이티브 분산 데이터베이스. 요즘 컴퓨팅 시대에는 모든 규모 있는 서비스들은 많은 언어로 개발되고 있다. 서비스의 많은 유즈 케이스를 잘 다루기 위해서는 관계형과 NoSQL 모두 필요하기 때문이다.
CDN #
유튜브는 구글의 글로벌 네트워크를 이용해서 콘텐츠 전송에 낮은 지연시간, 낮은 비용을 이룬다. 멀리 돌아왔다. 이제 어떻게 유튜브가 비디오를 저장하는지! Storage 얘기를 한다.
Data Storage - 유튜브는 미친 데이터 용량을 어떻게 저장하는가! #
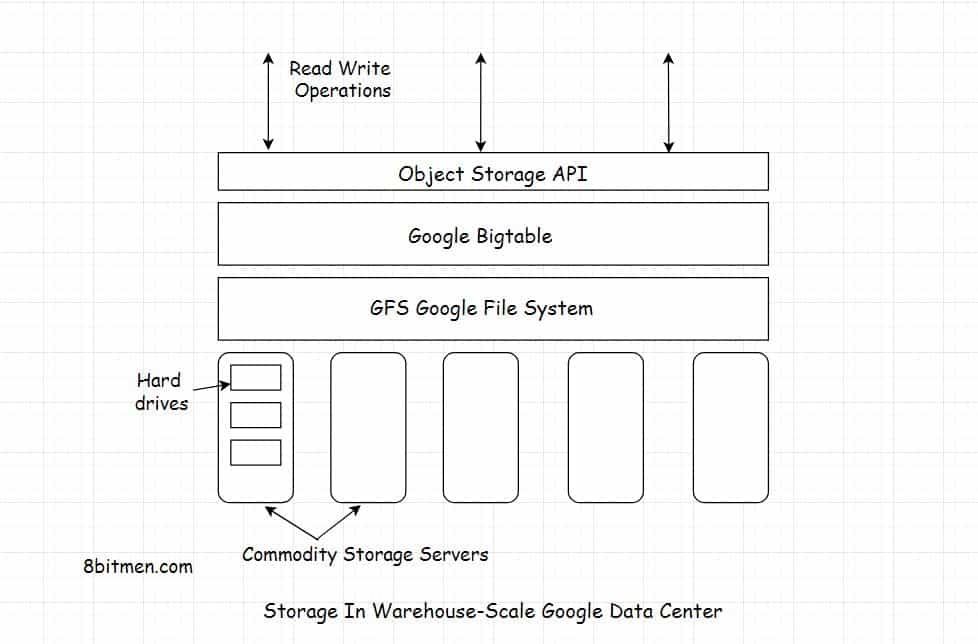
구글 파일 시스템(GFS, Google File System)
비디오들은 웨어하우스만한 크기의 구글 데이터센터 하드드라이브들에 저장된다. 데이터는 google file system과 BigTable로 관리된다.
GFS(google file system) #
많은 양의 데이터를 분산 환경에서 관리하기 위해 구글이 개발한 분산 파일 시스템
BigTable #
수천 대의 기계에 분산된 patabyte급의 데이터를 처리하기 위해 구글 파일 시스템 위에 구축된 저지연 분산 데이터 저장 시스템.
비디오는 HDD에 저장된다. 관계, 메타 데이터, 사용자 선호 정보, 프로필 정보, 계정 설정, 비디오를 가져오기 위해 필요한 관계 정보 등은 MySQL에 저장된다.